软件所在自监督多视角表示学习方面取得进展
软件所天基综合信息系统重点实验室研究团队的论文Information Theory-Guided Heuristic Progressive Multi-View Coding近日被计算机科学领域顶级学术期刊Neural Networks接收,第一作者为特别研究助理李江梦。论文从信息论的角度重新审视了自监督多视角表示学习(Self-supervised multi-view representation learning),并建立了相应理论框架,提出了一种启发式递进的方法,实验证明了该方法在自监督表示学习任务上对于基准方法的显著性能提升。
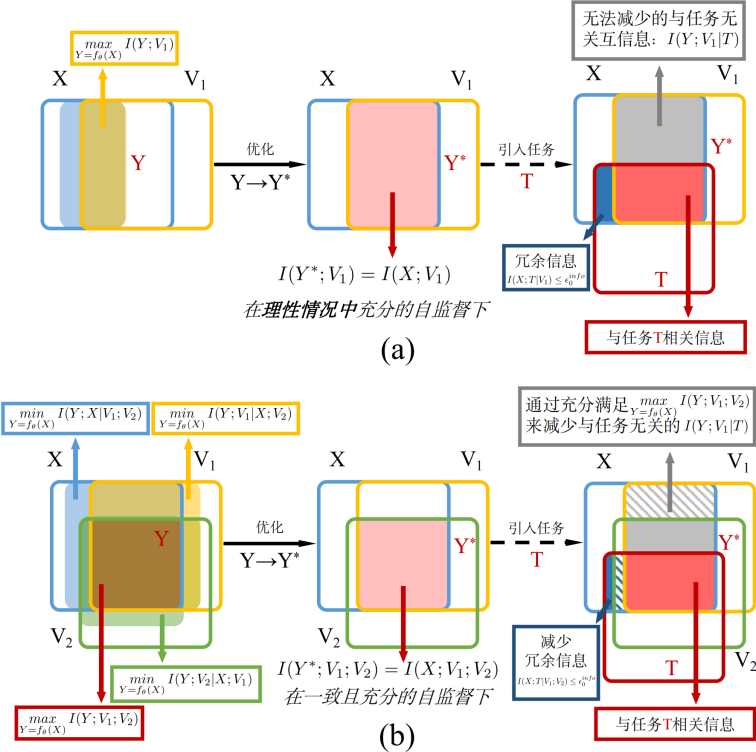
图1:基于信息论的分析,(a)传统自监督多视角学习方法,(b)本文提出的方法
自监督多视角表示学习方法是通过采用复杂的数据增强和特定编码器,在视角之间进行基于锚点的对比学习。这种基于成对学习范式所得到的自监督表示会受到特定视角的噪声、错误分配的假负样本和无差别测量样本对相似性等因素的影响。这些因素使得自监督多视角表示学习无法对多个视角的共享信息进行充分建模。
为了寻找上述因素对自监督多视角表示学习产生影响的本质原因,论文从信息论的角度进行分析,提出了一种基于信息论的泛化自监督多视角理论框架,来提升自监督多视角表示学习的可解释性,最后总结出当前该领域所存在的问题因素影响基于锚点对比学习的三个原因:1)视角特定的噪声导致了学习到的表示不一致; 2)错误分配的假负样本导致学习过程处于有偏见的自监督下,致使学习到的表示捕获了错误的判别性信息; 3)均匀测量相似度导致优化不稳定以及自监督不充分。由此,传统自监督多视角表示学习无法对视角共享信息进行充分建模。
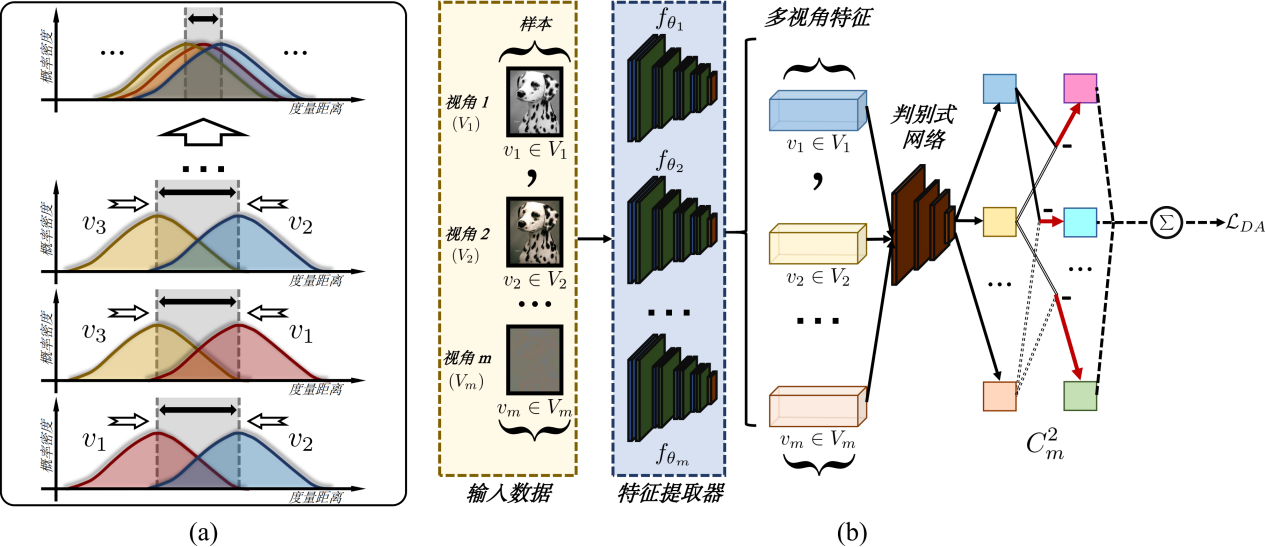
图2:分布层的视角对齐方法,(a)视角对齐概念示意图,(b)视角对齐算法图
在泛化自监督多视角理论框架的指导下,论文提出了一种启发式递进自监督多视角编码方法,该方法可以通过三层渐进式架构稳健地捕获视角共享信息。在分布层中,为避免不同视角的分布偏移导致共享语义信息无法充分获取的情况,论文通过最小化不同视角之间的差异度量(Discrepancy metric)来对齐不同视角的分布,以捕获视角共享语义信息并屏蔽任务无关的噪声信息。在集合层中,论文创新性地放弃了基于锚点的对比学习方法,而提出了基于池的自适应对比方法,来降低假负样本对学习过程的负面影响。在实例层中,论文采用统一损失函数,基于对比正确的优化贡献度来动态调整相应的梯度权重。
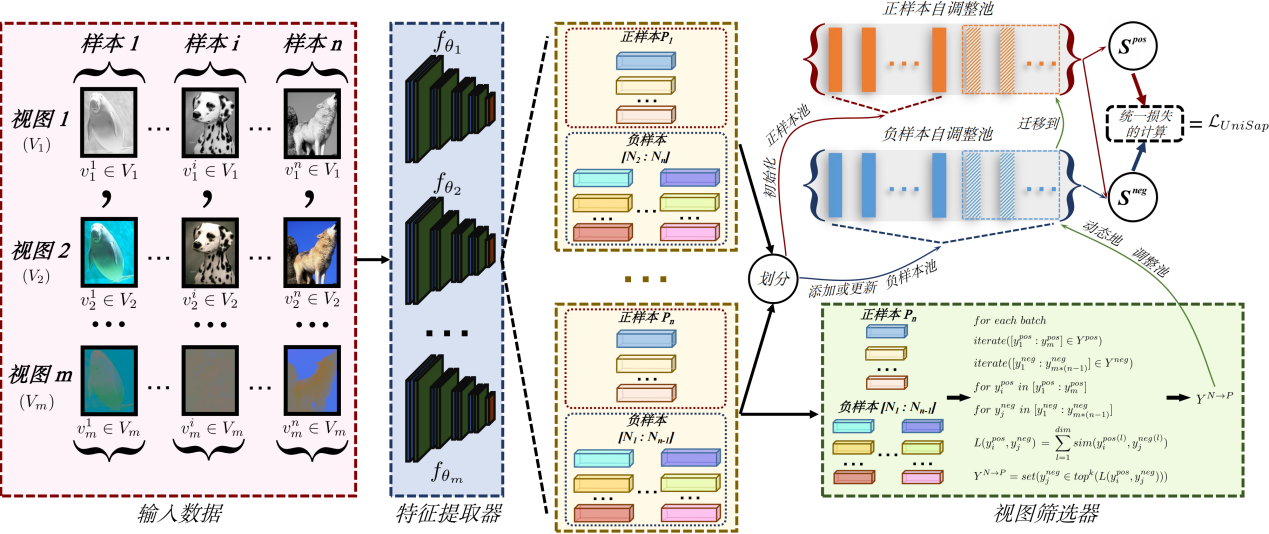
图3:集合层与实例层算法图
研究团队通过理论分析证明了论文所提出的方法可以有效提高所得到的多视角表示之间互信息的下界。该方法与多种不同的自监督方法在重要图像分类基准数据集上进行了对比(以Accuracy作为评价指标),结果表明,与最先进的基准方法相比,论文所提出的方法模型在ImageNet数据集上平均提升了1.30%,在Tiny ImageNet、CIFAR10、CIFAR100、STL-10等基准数据集上也取得了显著的效果。
此外,研究团队进一步在重要动作识别数据集上进行了实验对比,并发现论文所提出的方法模型在UCF-101以及HMDB-51数据集上都达到了最先进的性能。团队还通过消融实验证明了所提出方法的合理性。