软件所提出一种可同时表征学习模型迁移性和判别性的新型对抗框架
文章来源: | 发布时间:2026-01-27 | 【打印】 【关闭】
近日,中国科学院软件研究所天基综合信息系统全国重点实验室研究团队聚焦无监督领域自适应(UDA)的表征学习,提出一种新型的对抗式框架,能够显著提升表征学习模型对迁移任务的适应能力和判别能力。相关成果论文On the Transferability and Discriminability of Representation Learning in Unsupervised Domain Adaptation被人工智能领域顶级期刊IEEE TPAMI接收,第一作者为强文文副研究员,通讯作者为李江梦副研究员。
在无监督领域自适应的表征学习中,当前主流的对抗式方法通常仅通过分布对齐和源域经验风险最小化来保证可迁移性,往往忽视了目标域特征本身的可判别性。为了进一步提升表征学习模型性能,研究团队指出,“良好表征学习”应同时具备高迁移性和高判别性,并论证了仅优化迁移性可能导致目标域判别信息丢失的问题,因此有必要引入专门约束来增强目标域表征的判别能力。
基于这一思路,研究团队提出一种新型的对抗式无监督领域自适应方法——具有全局与局部一致性的领域不变表征学习RLGLC。该方法引入不对称放松的Wasserstein-of-Wasserstein距离(AR-WWD),构建全局一致性模块(GCM)以度量跨域分布差异,从而避免因分布强行对齐导致的分类偏差。同时,RLGLC还设计了局部一致性模块(LCM),通过对比学习方式保留目标域细粒度的判别信息,实现对目标域可判别性的约束。
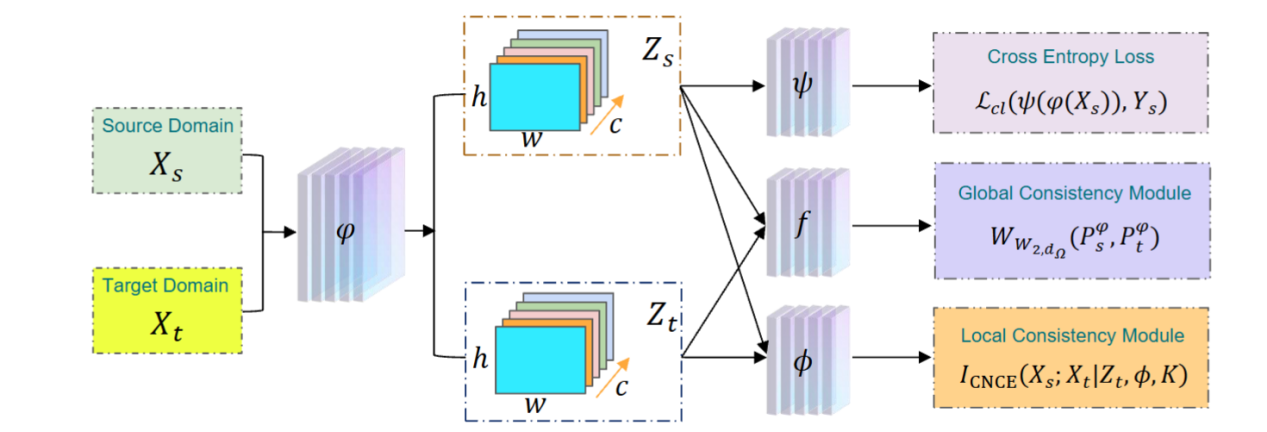
RLGLC方法框架
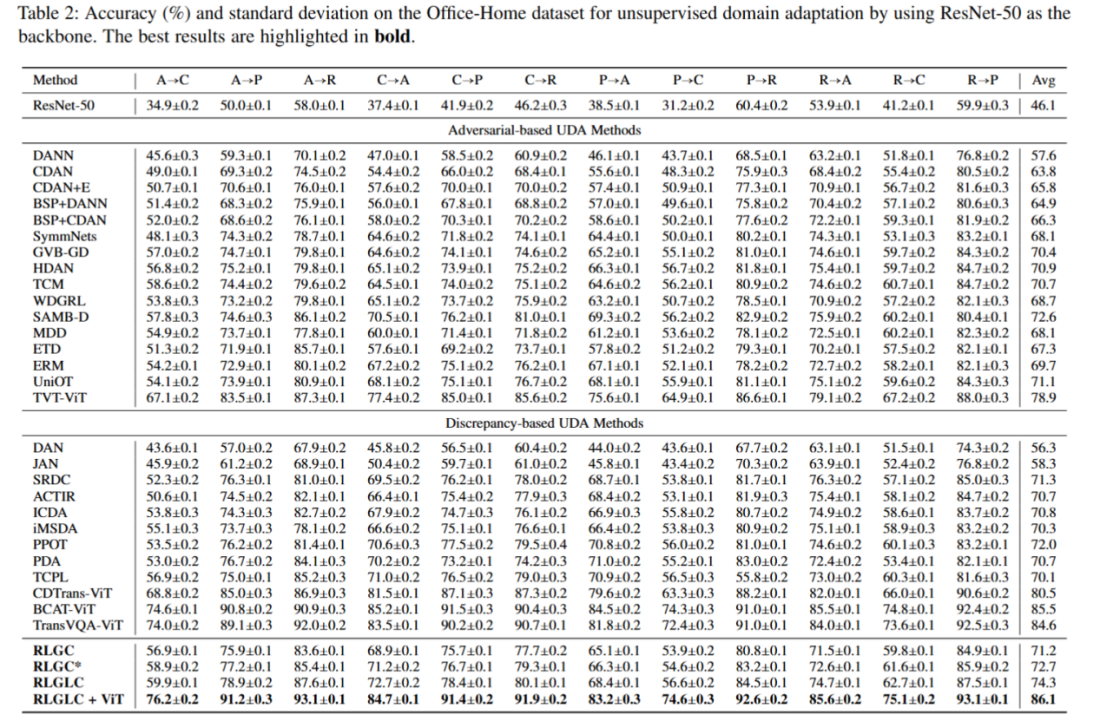
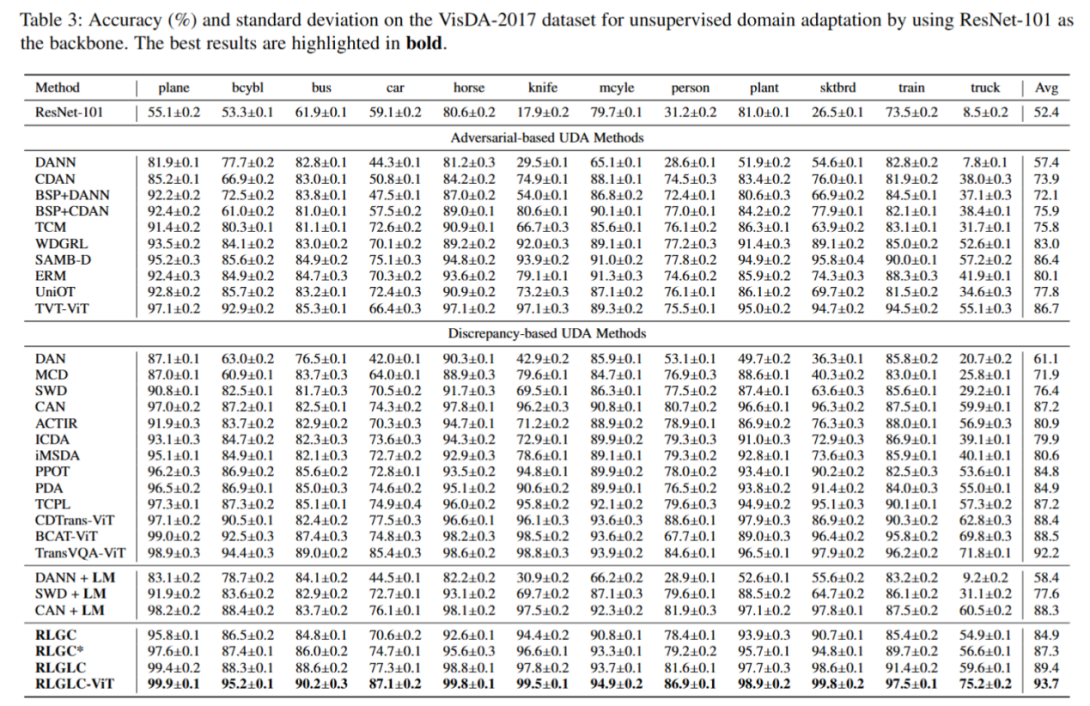
研究团队在多个标准领域自适应基准上对RLGLC进行了系统评估。所有实验均重复五次并汇报平均准确率,结果显示RLGLC在各项任务中整体优于现有对抗式UDA方法。在不同骨干网络与实验设置下,RLGLC均表现出优异的泛化能力和鲁棒性,尤其是在大规模、高难度的迁移任务中优势更为明显。此外,基于Friedman检验的统计分析进一步证实,RLGLC所带来的性能提升具有显著的统计学意义。