
软件所提出一种干预多模态表示学习方法
文章来源: | 发布时间:2026-06-18 | 【打印】 【关闭】
近日,中国科学院软件研究所天基综合信息系统全国重点实验室科研团队提出一种以泛化前门准则为基础的干预多模态表示学习方法,能有效提升多模态模型在模态不平衡场景下的性能。相关成果论文Interventional Imbalanced Multi-Modal Representation Learning via β- Generalization Front-Door Criterion被多媒体计算领域著名期刊IEEE Transactions on Multimedia (TMM) 录用,第一作者为博士生李懿和博士生宋飞,通讯作者为李江梦副研究员。
在多模态任务中,不同模态对预测结果的贡献往往不平衡,可相应划分为主模态和辅助模态。现有方法普遍在训练过程中增强辅助模态,以缓解模态贡献不平衡的问题。然而,研究团队发现,此类方法缺乏因果解释,且判别性知识挖掘能力有限。
针对上述问题,研究团队提出了干预多模态表示学习方法IMML。团队首先从结构因果模型角度建模多模态表示学习,提出在考虑辅助模态的同时,捕捉主模态中判别性知识与真实标签间的因果关系。进一步,团队设计了β-泛化前门校正模块,通过构造非配对模态组合、随机控制不同模态的比例贡献,有效削弱辅助模态中潜在的噪声干扰。此外,IMML还包含模态判别性知识探索模块,通过构建模态判别性知识网络,为特征维度分配权重,来充分挖掘对任务真正有用的判别性知识。
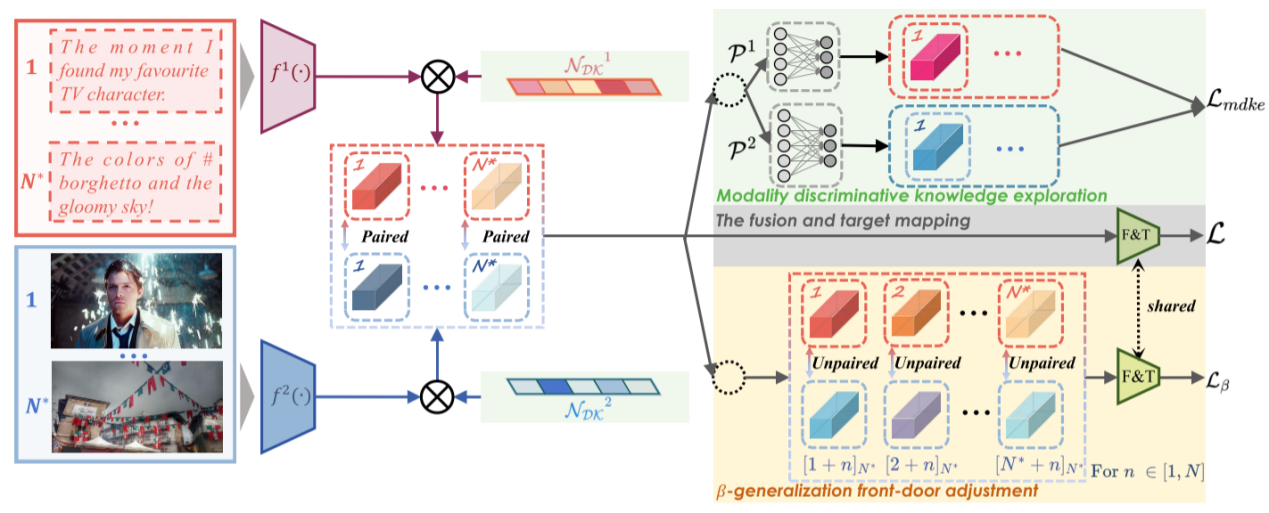
方法架构图
研究团队在Food101、MVSA-Single、MVSA-Multiple等多个多模态数据集上系统评估了IMML的性能。实验结果表明,引入IMML后,基准多模态学习方法在多个评估设置下均取得显著性能提升。例如,在MVSA-Multiple数据集上,QMF+IMML在噪声强度ϵ=5.0条件下达到66.53%的准确率,相比原始QMF提升1.72%;在HFM 数据集上,QMF+IMML在噪声强度ϵ=5.0条件下达到85.56%的准确率。上述结果验证了IMML在提升多模态表征判别能力与噪声鲁棒性方面的有效性。
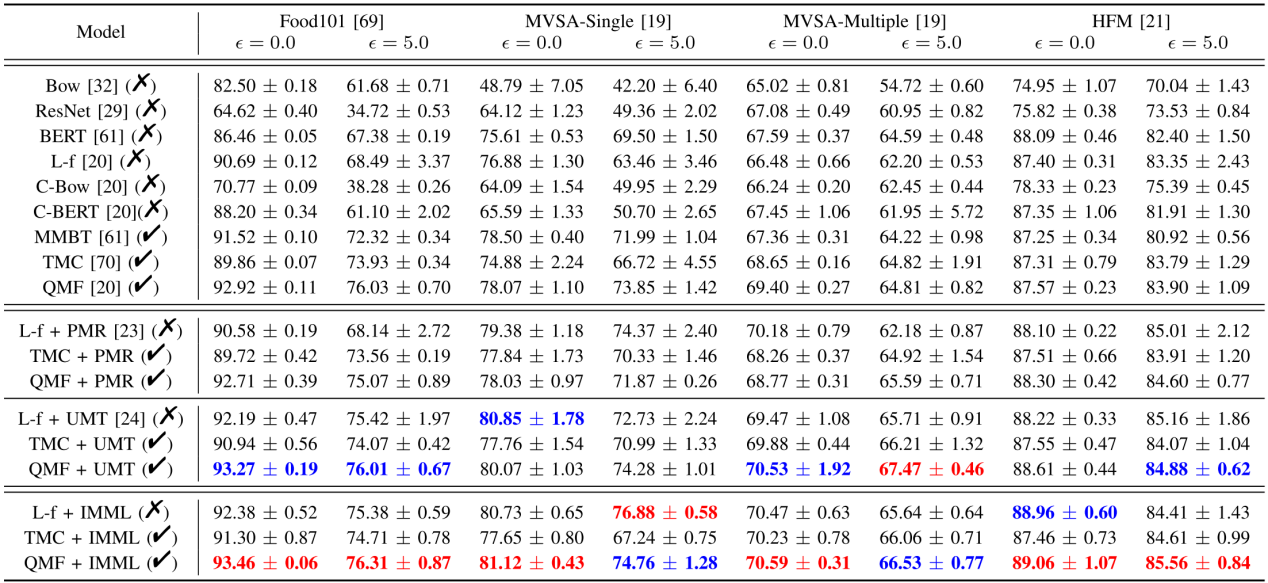
IMML在四个多模态数据集上的结果




