

软件所提出基于因果推理的视觉语言模型下游任务适应方法
文章来源: | 发布时间:2024-10-23 | 【打印】 【关闭】
近日,软件所天基综合信息系统全国重点实验室研究团队在机器学习领域国际顶级学术会议NeurIPS 2024发表题为Rethinking Misalignment in Vision-Language Model Adaptation from a Causal Perspective的论文,深入探讨了基础视觉语言模型在适应特定下游任务时面临的数据错位问题,并提出了一种创新的适应方法,显著提高了模型对新类数据的识别能力。论文共同第一作者为博士生张雅楠和特别研究助理李江梦,通讯作者为特别研究助理强文文。
近年来,诸如CLIP等基础视觉语言模型通过在大规模数据集上的训练,展现出了卓越的泛化能力。然而,在这类模型通过提示调优适应下游任务时,普遍存在数据错位,即测试时除了有用于训练的基类数据,还需在新类数据上进行评估。实验显示,随着训练进行,模型在基类上的性能持续提升,但在新类上的表现呈现先升后降的趋势。研究团队使用结构因果模型(SCM)对这一现象进行了分析,发现下游任务中基于基类估计的任务无关生成因子对新类来说往往是不准确的,被错误保留的任务无关生成因子成为了影响模型性能的混杂因子。
为了减轻混杂因子的干扰,研究团队提出了一个名为因果驱动的语义解耦与分类方法CDC,通过前门调整来提升模型新类识别的能力。该方法由两个核心模块组成:第一个模块为语义解耦模块,旨在从输入数据中提取并解耦不同的语义特征;第二个模块为可信分类模块,能够处理多个独立的特征输入,评估对应输出的不确定性,并将结果进行融合。这两个模块互相配合,共同实施前门调整,以估计输入图像及其类别之间的真实因果关系,来增强对新类数据的识别能力,减轻了与任务无关的生成因子对模型性能的负面影响。
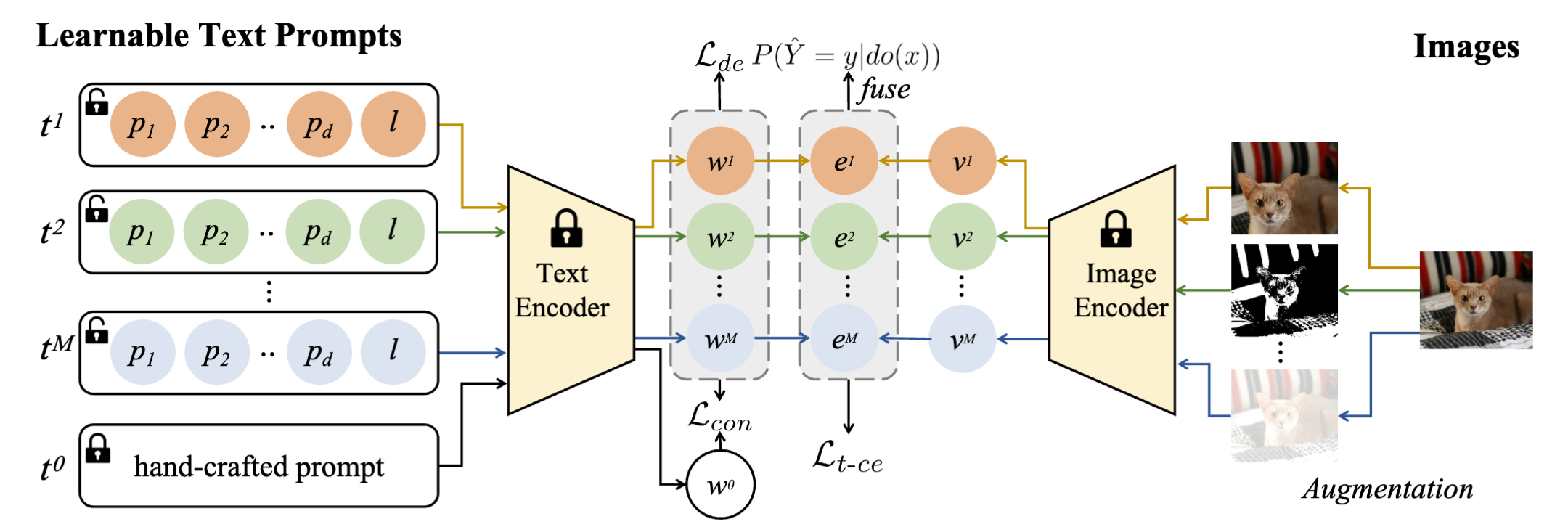
因果驱动的语义解耦与分类方法(CDC)框架图
研究团队进一步在Base-to-New、跨数据集OOD泛化、跨域OOD泛化三种不同的实验设置下进行了验证。结果表明,在不同的实验设置下引入CDC均能实现稳定的性能提升。特别是在Base-to-New实验中,CDC在HM指标上相较基线方法MaPLe实现了较为明显的平均性能提升。
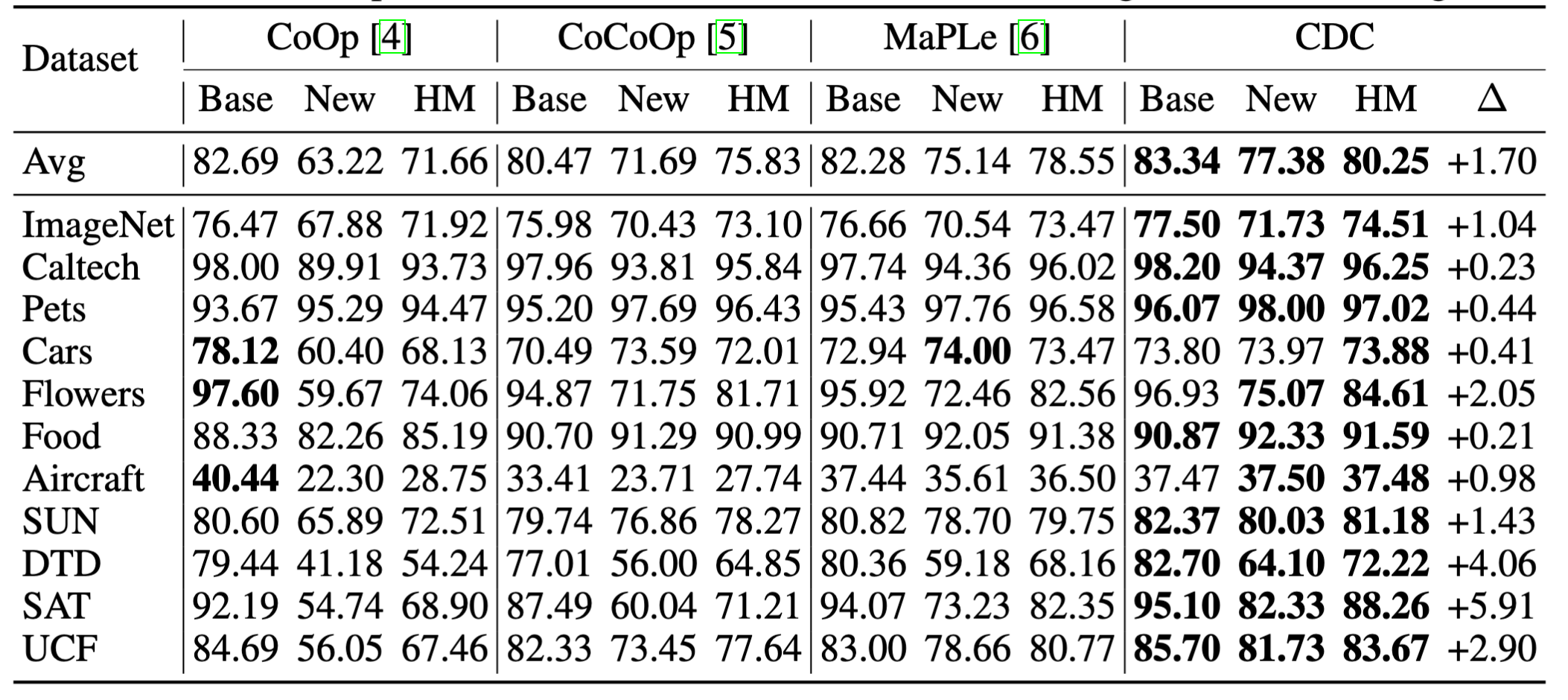
Base-to-New设置下的实验结果
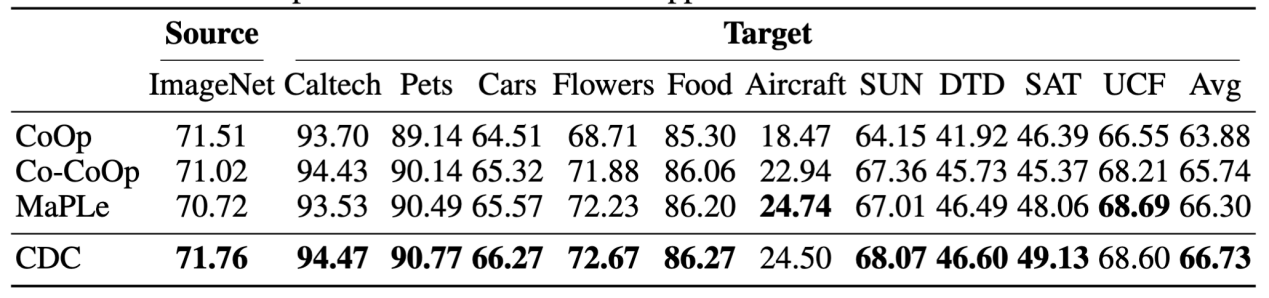
跨数据集OOD泛化设置下的实验结果
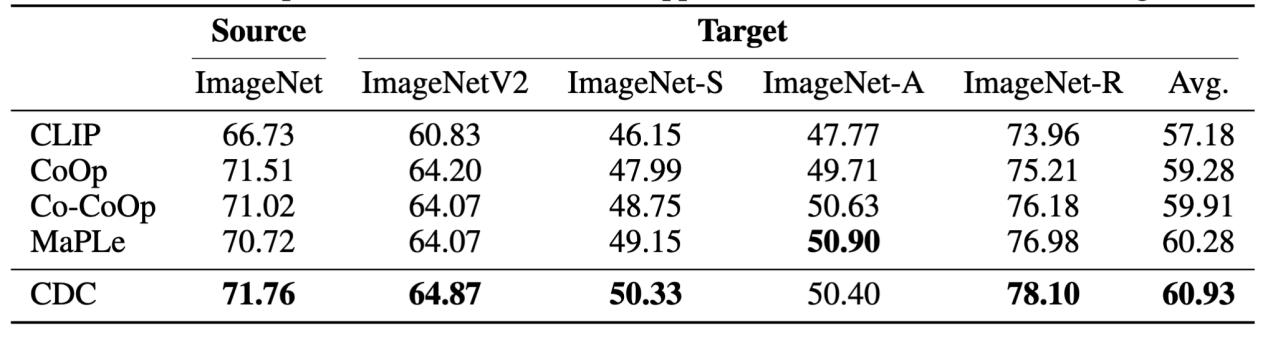
跨域OOD泛化设置下的实验结果
论文链接:https://arxiv.org/abs/2410.12816




