
软件所天基综合信息系统全国重点实验室多篇论文被AAAI 2026、IJCV录用
文章来源: | 发布时间:2026-01-15 | 【打印】 【关闭】
近日,中国科学院软件研究所天基综合信息系统全国重点实验室多篇论文被人工智能领域国际会议40th Annual AAAI Conference on Artificial Intelligence(AAAI 2026)及计算机视觉领域顶级期刊International Journal of Computer Vision(IJCV)录用。以下是成果介绍,欢迎大家交流讨论。
1. TMAE: Learning Targeted Multi-Agent Exploration via Causal Inference
作者:孙楚雄、姚敦琦、王瑞、强文文、郑昌文、李江梦
录用会议:AAAI
内容简介
多智能体强化学习在解决复杂现实问题时常面临“稀疏奖励”的挑战,即智能体在广阔的探索空间中难以捕捉有效的反馈信号。现有方法主要是通过引入内在奖励(如好奇心、多样性)来增强探索,或利用降维技术将高维状态映射到低维潜在空间。前者难以随智能体数量增加而有效扩展,后者则往往无法准确反映奖励的真实结构。
面对上述问题,研究团队提出了一种名为Targeted Multi-Agent Exploration(TMAE)的目标导向探索框架。该框架通过构建结构因果模型来描述子状态变量与稀疏奖励之间的因果关系。为消除历史轨迹等复杂因素的干扰,TMAE引入了反事实因果干预技术,通过计算平均因果效应(ACE)精准量化各子空间的重要性,从而引导智能体优先关注具有更强因果效应的关键区域。
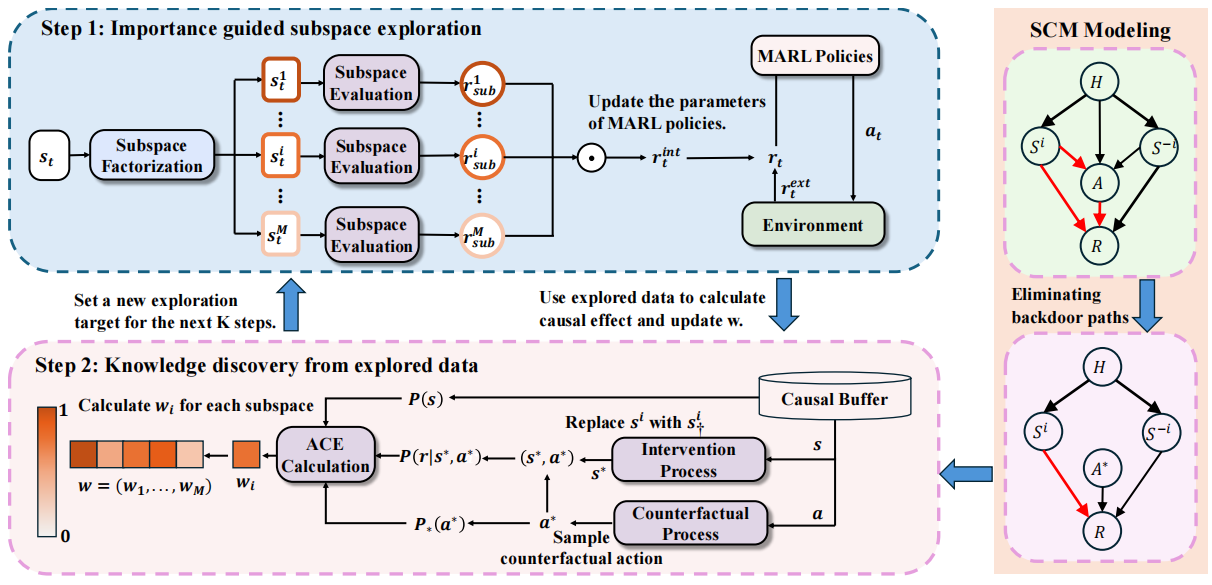
TMAE的方法框架图
在Google Research Football和StarCraft Multi-Agent Challenge(SMAC)等多个实验场景下,TMAE在探索性能上显著优于当前主流算法。可视化分析显示,该框架能够自动识别如“敌方残血状态”“技能冷却时间”等优先因素,这一结果不仅与领域先验知识相符,也增强了多智能体探索过程的可解释性。
2. M2I2: Learning Efficient Multi-Agent Communication via Masked State Modeling and Intention Inference
作者:孙楚雄、贺鹏、戢启瑞、臧泽华、李江梦、王瑞、王微
录用会议:AAAI
内容简介
在部分可观测环境中,多智能体需要借助通信共享局部观测,以形成更完整的信息理解。当前通信方法主要侧重于发送端的设计,而接收端往往是简单拼接或聚合通信信息与本地观测,在带宽有限的情况下易丢失关键信息或引入冗余,影响决策质量。
因此,研究团队将通信后的信息整合,建模为一个具有结构约束和明确优化目标的表征学习问题。在此思路基础上,研究团队提出了通信方法M2I2。该方法主要包括两方面设计:在发送端引入维度理性网络,基于元学习评估观测各维度对强化学习目标的重要性,实现选择性共享关键信息;在接收端,通过注意力编码器融合多智能体信息,并结合掩码状态建模与联合动作预测两类互补约束,促使通信表征在重建关键环境状态的同时,能推断队友行为意图,更有效地支持协同决策。
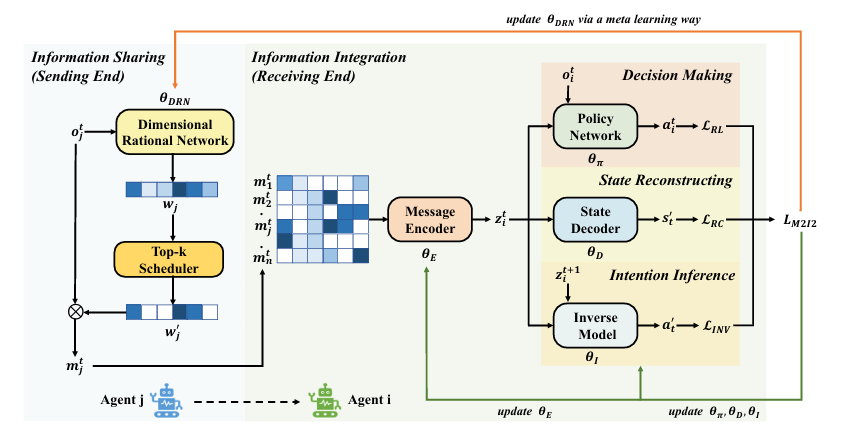
M2I2的方法框架图
在Hallway、MPE及SMAC等多种经典多智能体基准环境的实验中,M2I2在最终任务回报、胜率、训练稳定性以及通信效率等方面均优于其他代表性通信方法,并在不同算法框架下展现出良好的泛化性与可复用性。
论文链接:https://arxiv.org/abs/2501.00312
3. Adversarial Attack on Black-Box Multi-Agent by Adaptive Perturbation
作者:陈建明、王亚文、王俊杰、谢肖飞、胡渊喆、王青、徐帆江
录用会议:AAAI
内容简介
作为可靠性测试技术,现有的多智能体系统对抗性攻击方法在实用性和灵活性上仍存在一定局限:其一,许多方法依赖于白盒信息或高控制权限,难以在实际黑盒场景中部署;其二,现有方法通常针对所有智能体进行无差别攻击,或面向其中某些特定固定智能体,缺乏不同系统状态与攻击目标的自适应性。
为此,论文提出了一种面向黑盒多智能体系统的自适应可靠性测试方法AdapAM。该方法采用自适应选择策略,动态确定受攻击的智能体及其预期恶意动作,以最大化影响多智能体系统性能。此外,AdapAM基于代理模型的诱导攻击机制,通过生成对抗模仿学习,训练出近似目标多智能体系统的代理模型,从而能借助该模型的白盒信息生成扰动观测,在黑盒条件下诱导受攻击智能体执行所选恶意动作。
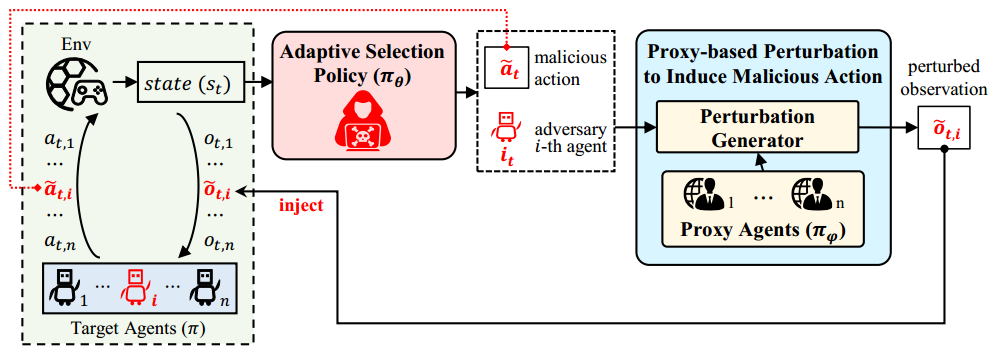
方法概览图
在八个常用多智能体测试环境的实验表明,AdapAM能够有效对黑盒多智能体系统进行可靠性测试。相较于四个基线,AdapAM在不同扰动率下都能够发现更多的系统风险,同时产生最小的扰动噪声。
论文链接:https://arxiv.org/abs/2511.15292
4. HTG-GCL: LeveragingHierarchical Topological Granularity from Cellular Complexes for Graph Contrastive Learning
作者:戢启瑞、秦滨、靳毅凡、赵云泽、孙楚雄、郑昌文、曹建文、李江梦
录用会议:AAAI
内容简介
现有图对比学习方法通常依赖删边等随机结构扰动,难以有效刻画复杂数据中存在的高阶拓扑关系。近期相关研究尝试将图提升成单一粒度的胞腔复形,以显式引入高阶结构信息。然而,研究团队实验发现,不同数据集对拓扑粒度的敏感度不同,选错提升粒度可能损害模型性能。
据此,研究团队提出了一种分层拓扑粒度图对比学习框架HTG-GCL。在数据表示方面,HTG-GCL将原始图统一转换为基于最大环长差异的多个粒度的胞腔复形视图,形成由粗到细的分层拓扑粒度表示;在学习机制方面,该框架在预训练阶段采用多粒度解耦对比学习,为每种粒度构建独立对比空间,并结合基于狄利克雷不确定性估计的粒度加权策略,自适应抑制不可靠拓扑视图、增强高置信度粒度的贡献,实现对多层拓扑信息的有效融合。
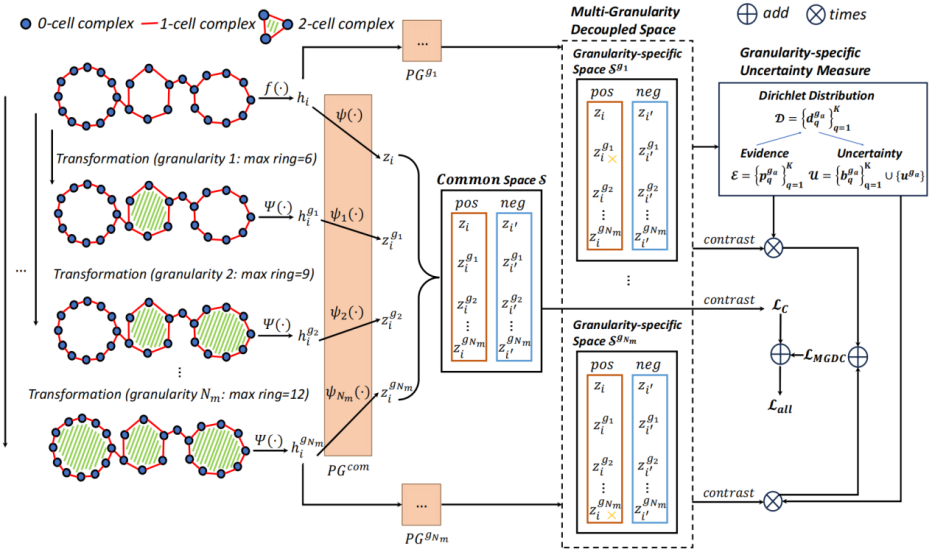
HTG-GCL框架图
研究团队在涵盖生物分子图与社交网络图等多个领域的6个TU基准数据集上进行了系统评估,覆盖无监督与半监督图表示学习两种设置。实验结果表明,HTG-GCL在无监督和半监督场景下均以1.0的平均排名在所有数据集上取得最优性能,验证了分层拓扑粒度建模与多粒度解耦对比学习策略在图对比学习中的有效性。
论文链接:https://arxiv.org/pdf/2512.02073
5. DoublyDebiased Test-Time Prompt Tuning for Vision-Language Models
作者:宋飞、李懿、王瑞、周嘉欢、郑昌文、李江梦
录用会议:AAAI
内容简介
作为一种无标注数据的适配方式,测试时提示调优(TPT)方法在应对测试时领域偏移问题上已展现出优越性能。然而,仅依赖未标注的测试数据进行提示优化的方式直观上是不足的,可能会导致提示优化偏差。
对此,研究团队提出了双重去偏测试时提示调优方法D²TPT,通过引入面向图像和文本输入的模态特定可学习提示,并设计了两部分模块来共同减轻提示优化偏差。一是动态检索增强调控模块,通过引入动态知识库,存储高置信度预测并支持动态更新,从而实现基于测试输入的特征检索和预测调控;二是可靠性感知的提示优化模块,采用了基于置信度的加权集成策略来增强视图的判别信息,同时设计了跨模态一致性蒸馏策略,促进图像和文本模态在共享嵌入空间的语义一致性。
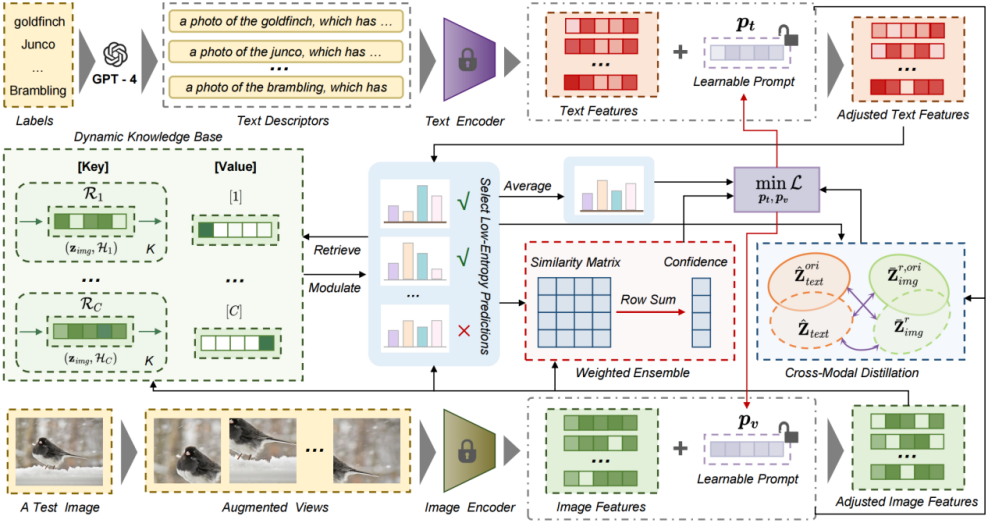
D²TPT框架图
研究团队在涵盖自然分布变化和跨数据集泛化场景的15个基准数据集上进行了评估。实验结果表明,D²TPT相比基准方法取得了显著性能提升,并实现了最高的平均准确率,验证了其在处理具有不同分布和标签语义的多样化视觉领域中的泛化能力。
论文链接:https://arxiv.org/abs/2511.11690
6. Group Causal Policy Optimization for Post-Training Large Language Models
作者:顾子茵、王婧瑶、左然、孙楚雄、宋泽恩、郑昌文、强文文
录用会议:AAAI
内容简介
针对大语言模型在多候选强化微调的推理优化问题,现有方法Group Relative Policy Optimization(GRPO)利用组内相对奖励、避免昂贵的价值函数学习,具有较高效率。然而,GRPO将候选答案视为相互独立,仅基于组内相对奖励更新策略,未能有效利用候选间可能存在的互补或冲突结构。同时,在集成最终答案过程中隐含形成的因果对撞结构也未被考虑,导致部分重要因果信息未被利用。
为此,研究团队从“查询-候选解-集成答案”的推理过程出发,构建结构因果模型进行分析,发现在对撞结构下,将候选输出投影到满足因果约束的子空间有助于系统性降低测试误差,由此提出方法Group Causal Policy Optimization(GCPO)。该方法主要包括两部分,一是为每个候选构建因果投影基线,将奖励标准分解为相对得分和与因果基线一致性得分,优先强化与主流合理推理路径相容的候选;二是在KL正则引入因果增强参考分布,将查询条件分布和经因果投影校正分布结合,引导策略更好对齐由对撞结构所揭示的支持/冲突关系。
在多个数学与代码推理基准上的评估表明,GCPO在1.5B/7B等不同规模的基座模型上,性能均显著优于GRPO、GVPO、Dr.GRPO等方法。此外,梯度范数可视化表明,GCPO训练轨迹更平滑、策略方差更低,说明引入的因果结构建模提升推理性能的同时,也带来了更稳定的优化过程。

大语言模型采样轨迹示例
论文链接:https://arxiv.org/abs/2508.05428
7. Exploring Transferability of Self-Supervised Learning by Task Conflict Calibration
作者:郭慧杰、王婧瑶、郭沛正、沈星辰、郑昌文、强文文
录用会议:AAAI
内容简介
现有自监督学习的表征迁移方法,通常默认将同一批次中的不同样本视为独立同质的训练单元,但实际情况往往更复杂。不同数据增强方式可能引入具有不同语义偏向(如局部纹理、整体结构或语义一致性扰动等)的样本,造成任务冲突。在引入显式的任务级结构后,将可能导致迁移性能不稳定,出现不同训练轮次波动显著、梯度方向互相干扰等现象。
针对上述问题,研究团队提出了任务冲突校准方法Task Conflict Calibration(TC²)。主要包括两方面工作:一是通过构建因果因子提取网络,从多子任务中学习一组可重构且正交的因果生成因子作为语义基础,以区分任务间的共享成分与任务特有成分;二是设计权重提取网络,为样本学习稀疏的任务特有语义权重,使其仅激活与对应子任务相一致的因子,从而显式定位潜在冲突来源。在此基础上,TC²将表征投影到与子任务结构一致的子空间,并引入两阶段双层优化框架联合学习生成因子、稀疏权重与SSL表征,实现对表征的因果校准,抑制结构性冲突。
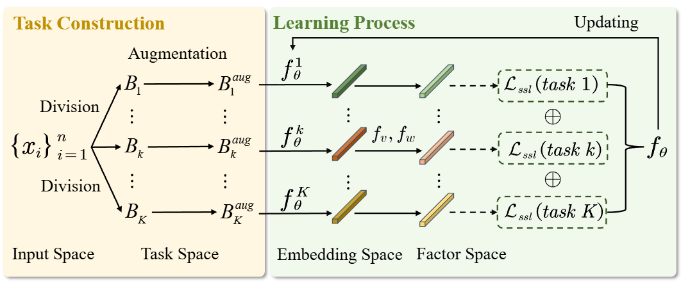
方法框架图
在ImageNet、Colored MNIST、PACS等多个视觉基准数据集以及分类、检测、迁移学习等多种下游任务的实验表明,TC²在多种自监督学习框架均能带来显著且稳定的迁移性能提升。同时,梯度相似度分析显示,TC²能有效缓解子任务间的结构性冲突,获得更具可迁移性的自监督表征。
论文链接:https://arxiv.org/abs/2511.13787
8. Causal Reward Adjustment: Mitigating Reward Hacking in External Reasoning via Backdoor Correction
作者:宋锐科、宋泽恩、郭慧杰、强文文
录用会议:AAAI
内容简介
对于大模型在外部推理流程中存在的奖励黑客问题,研究团队指出当前奖励模型在实际应用往往受语义混杂因素干扰,倾向于学习观察数据中的伪相关,从而对形式连贯但逻辑错误的推理步骤赋予高分,导致搜索算法误选错误路径。而现有方法通常依赖扩大模型规模或增加采样次数,无法从根源上消除语义偏置,难以保障推理系统的逻辑可靠性。
针对这一问题,研究团队使用结构因果模型(SCM)显式刻画推理步骤、奖励标签与潜在语义混杂因素之间的因果关系,并据此提出了一种基于因果后门校正的外部推理方法Causal Reward Adjustment(CRA)。一方面,引入特征解耦与混杂识别机制,通过在奖励模型内部激活,训练稀疏自编码器(SAE)提取可解释特征,并利用统计检验筛选出导致评分偏差的关键混杂变量;另一方面,实施因果后门调整策略,在识别特征上施加替代值并结合先验分布,估计消除混杂影响后的真实因果奖励,以替代原始评分引导搜索过程。
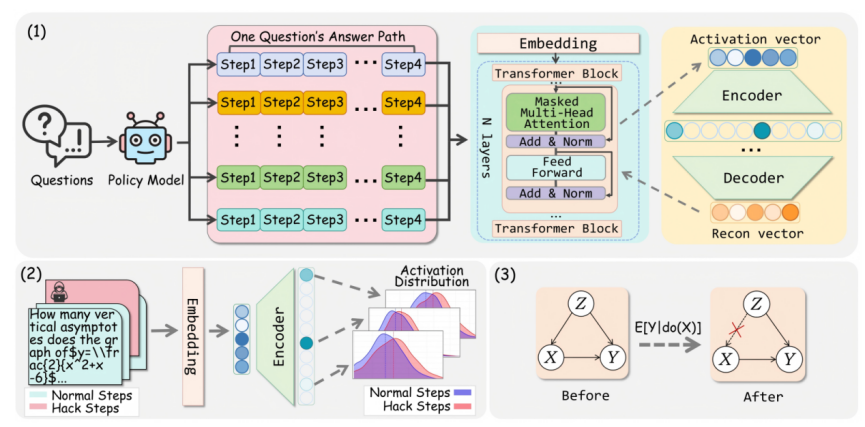
方法框架图
在GSM8K、MATH等典型数学推理基准的实验表明,CRA在保持模型结构完全冻结的情况下,性能显著优于传统采样扩展或启发式排序方法。同时,消融实验与特征分布分析显示,该方法有助于减少奖励黑客现象,表明引入因果干预机制不仅能提升答案准确率,也为大模型外部推理系统提供了兼具高可解释性与低部署成本的可信增强方案。
论文链接:https://arxiv.org/abs/2508.04216
9. Runtime Safety and Reach-avoid Prediction of Stochastic Systems via Observation-aware Barrier Functions
作者:冯胜华、安杰、徐帆江
录用会议:AAAI
内容简介
随着人工智能、自动控制、自动驾驶等技术的发展,随机动态系统已广泛应用于交通、机器人、金融、医疗等关键领域,而系统的安全概率预测问题是其可靠性保障的核心。现有安全和可达概率评估方法多基于离线建模,难以融入运行时动态变化的观测信息,导致估计结果往往偏保守、缺乏实时性,也难以动态融合新观测数据,限制了预测的精度和适应性。
针对上述挑战,研究团队提出了一种融合实时观测信息的观测自适应栅栏函数方法,理论上将传统栅栏函数推广至可融合观测的随机系统,建立了观测序列与概率下界之间的严密的数学关联。在算法实现上,框架分为离线与在线两阶段:离线阶段通过半定规划合成初始栅栏函数;在线阶段则设计反向迭代更新算法,根据新观测快速修正概率估计,提升方法的实时性与适应性。
研究团队在多个随机系统基准(如Van der Pol振子、Duffing系统等)上进行了测试。结果显示,该方法不仅具备较短的在线计算效率,并能借助观测信息优化概率估计,表现出良好的自适应性。与传统离线方法相比,安全和可达概率预测更为精准可靠,有力支撑了在线风险评估与动态决策。
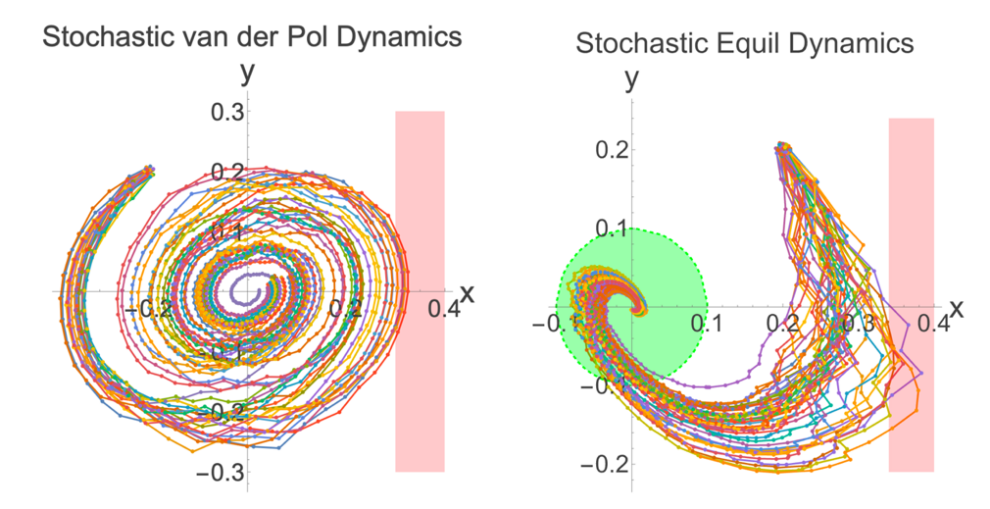
安全概率与到达规避概率预测结果
10. AmPLe: Supporting Vision-Language Models via Adaptive-Debiased Ensemble Multi-Prompt Learning
作者:宋飞、李懿、李江梦、王瑞、郑昌文、徐帆江、熊辉
录用期刊:IJCV
内容简介
多提示学习方法已成为在资源受限条件下促进视觉-语言模型快速适配下游任务的一种有效手段。然而,现有的多提示学习方法主要聚焦于在单一基础视觉-语言模型中设计并使用多种提示,忽略了其中潜在的模型-提示匹配偏差和样本-提示匹配偏差。
针对上述问题,研究团队提出了自适应去偏集成多提示学习方法AmPLe。一方面,基于集成学习的思路,对不同视觉-语言模型在多提示下获得的多样化预测结果进行聚合,从而最大化多提示在不同模型上的互补引导优势,有效降低模型-提示匹配偏差;另一方面,在信息论分析的指导下,从输入样本中学习与提示相关的语义信息,并基于该信息自适应地计算去偏集成权重,从而缓解样本-提示匹配偏差。
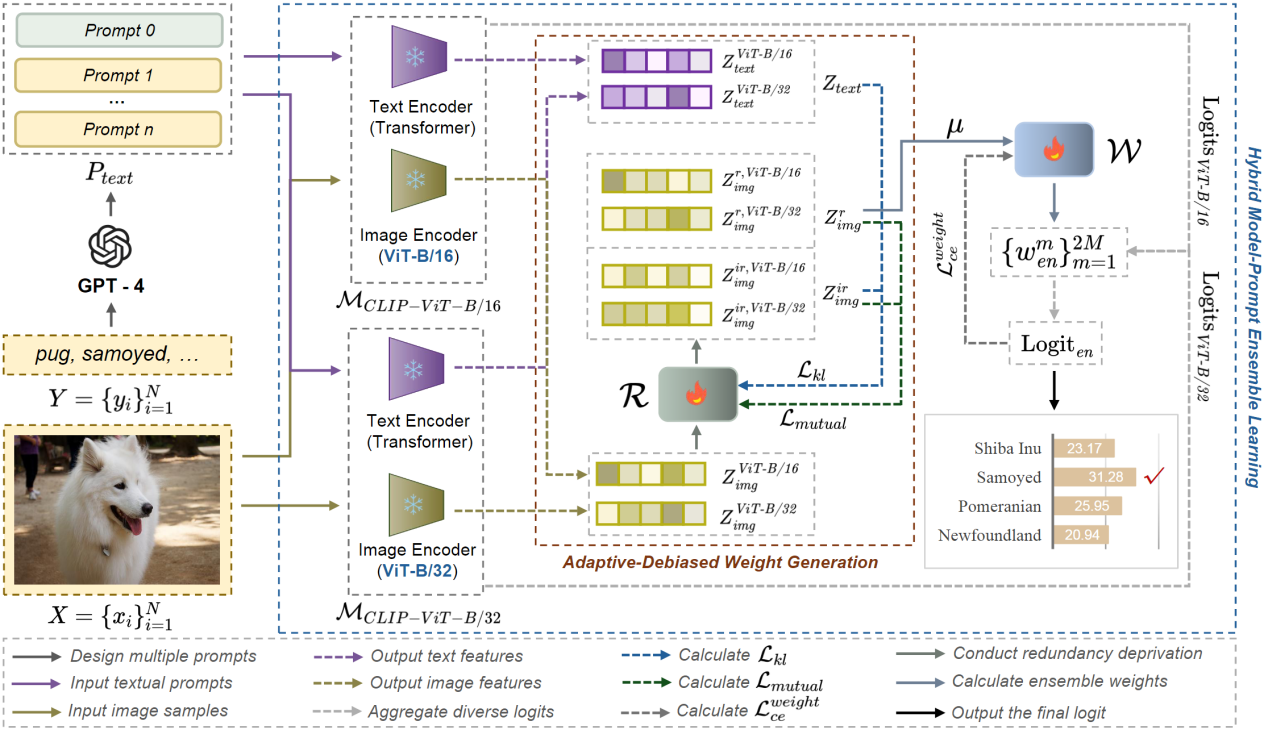
模型框架图
实验结果充分验证了AmPLe方法的有效性。集成AmPLe的模型在新类别泛化任务中的大多数数据集上表现优越,其调和均值(Harmonic Mean, HM)显著超过基线方法;在新目标数据集适配任务,平均性能获得了一致提升;在未知领域偏移任务的多个数据集上,均表现出明显性能增益并达到最高平均准确率,进一步展示了AmPLe的稳健性与有效性。




