软件所提出一种两阶段信号时序逻辑生成框架
近日,中国科学院软件研究所天基综合信息系统全国重点实验室研究团队聚焦信息物理系统中信号时序逻辑(Signal Temporal Logic, STL)生成难题,结合大语言模型增强和符号化方法,提出一种具有结构化中间表示的两阶段信号时序逻辑生成框架STLGen,有效提升了STL的生成精度与语义一致性。相关成果论文LLM-Enhanced Two-Stage STL Generation with Structured Intermediate Representation在电子设计自动化领域顶级会议Design Automation Conference(DAC 2026)上发表。论文第一作者为博士生青鸿菁,通讯作者为安杰副研究员、徐帆江研究员。
STL生成是将自然语言描述的系统需求转换成形式规约语言,是形式化方法保障嵌入式系统安全可靠运行的重要前提。然而,自然语言具有模糊、多变的特性,要转换为语法规则严格、语义表达精准的STL,仍存在诸多挑战。一是当前大语言模型方法忽视STL语法结构单步生成,难以捕捉嵌套模态,易出现语义偏离用户意图的问题。二是现有自动化数据集构建缺少闭环验证,仍需人工调整。三是当前评估指标存在缺陷,表现为语法指标仅校验模板匹配,未评估结构偏差对逻辑有效性的影响;语义指标因STL语义等价性不可判定,高度依赖人工评估。
针对上述问题,研究团队提出了两阶段生成框架STLGen,核心在于应用大语言模型增强,引入结构化自然语言(NL2)作为中间表示,衔接自然语言输入与STL输出并保留语义。一阶段是结构化提示工程模块,通过语义理解、规则标准化及纠错机制,将非结构化自然语言转为规范NL2。二阶段是NL2-STL转换器模块,先将NL2提取解析为符号化语法树,利用树形结构捕捉蕴含的嵌套模态,再通过符号映射、原子命题翻译完成STL语法元素替换。
此外,研究团队提出将符号化方法与大语言模型结合的自动化数据集构建方法,由随机STL经STL-to-NL2算法映射生成NL2-STL数据集,STL双路径转NL2并闭环验证后自动化生成NL-NL2数据集。利用新构建的数据集,通过指令微调和低秩适配技术对两阶段模型分别优化,有效提升生成精度。针对当前评估指标存在的不足,研究团队进一步提出了结构准确率和STL-SCOTES两项新自动化指标。结构准确率通过将STL公式分解为语法树,进行节点级匹配量化结构对逻辑正确性的影响;STL-SCOTES从参考的STL公式合成轨迹,通过评估候选公式对轨迹的满足性,量化语义一致性。
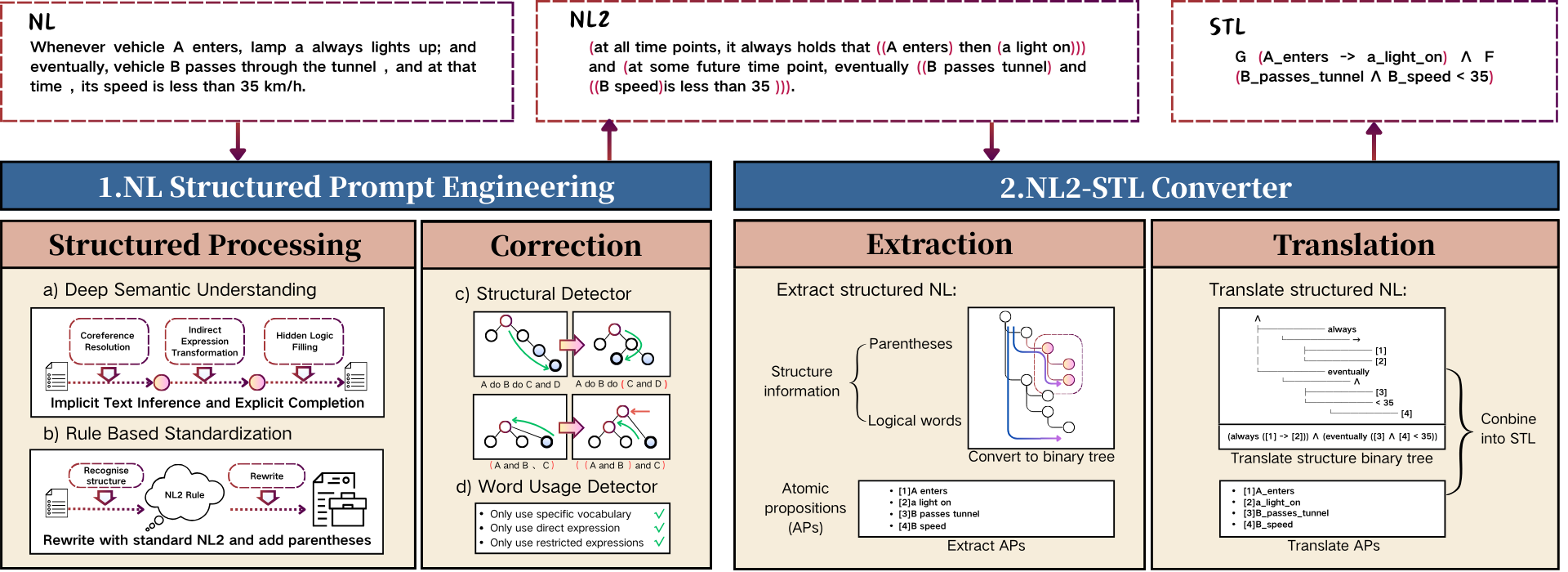
STLGen框架图
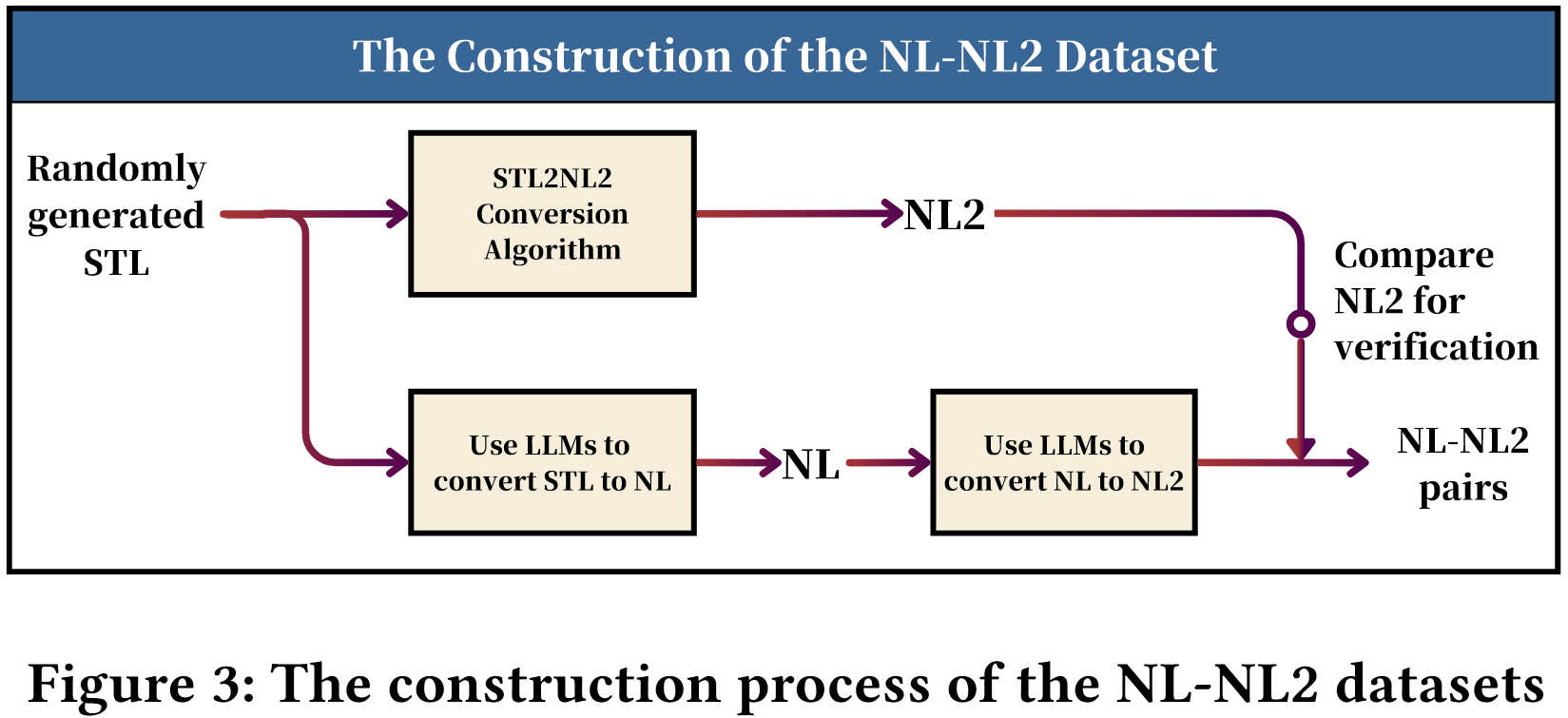
STL双路径转NL2并闭环验证过程
研究团队在STL-DivEn和DeepSTL两大标准数据集上进行了对比实验。结果显示,STLGen在经典指标、结构准确率和STL-SCOTES的指标评估结果均优于DeepSTL、GPT-3.5、GPT-4、GLM-4等六种基线模型。
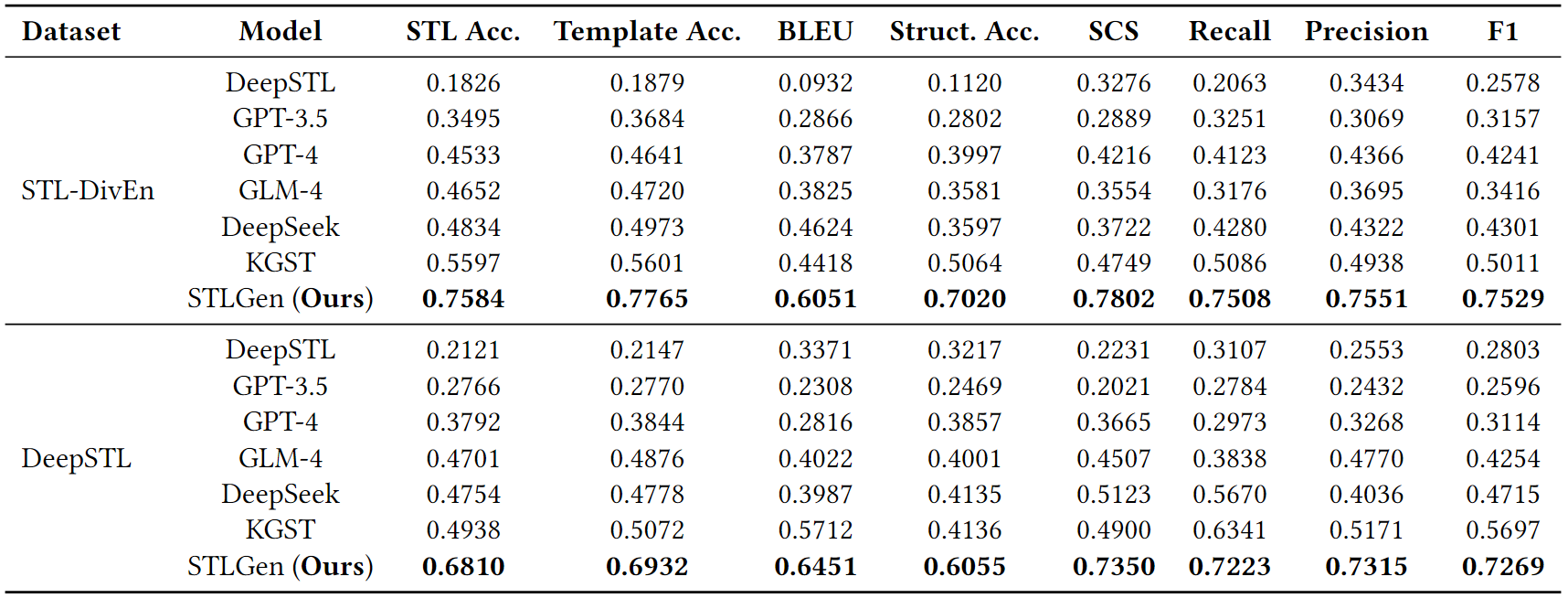
对比实验结果